키워드로 기술 자료 검색
개요:
전자실험노트(ELN)는 사진, 플레이트, 화학 편집기, 생성 등 다양한 기능이 포함된 페이지를 사용할 수 있는 서식 있는 텍스트 편집기를 제공합니다. LabCollector 시약 및 소모품 링크, Word 문서에서 직접 복사하여 붙여넣기 등. 또한 그래프 생성을 위한 다양한 스프레드시트도 제공합니다. ELN Flatspreadsheet(단순) 및 Zoho 스프레드시트(Excel과 유사)의 2가지 그래프를 제공합니다.
플랫 스프레드시트를 시작하려면 아래 단계를 따르세요.
1. 단축키 안내
2. 사용할 수식
3. 그래프 만들기
![]()
1. 바로 가기 안내
- 플랫 스프레드시트를 사용하면 플랫 스프레드시트를 탐색하는 데 도움이 되는 바로가기 가이드를 사용할 수 있습니다.
- 그것을 열려면 다음으로 이동하세요. 홈 -> 예약 -> 실험 -> 페이지 -> 플랫 스프레드시트 -> 편집 -> 바로가기 가이드.
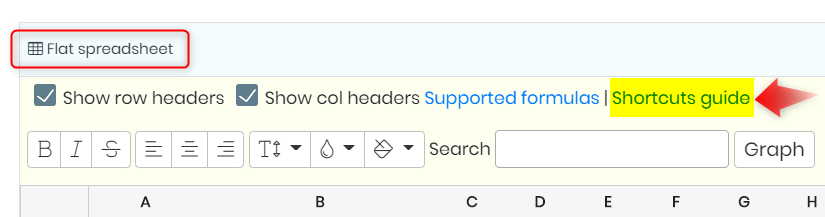
- "단축키 가이드"를 클릭하면 아래 옵션이 표시됩니다.


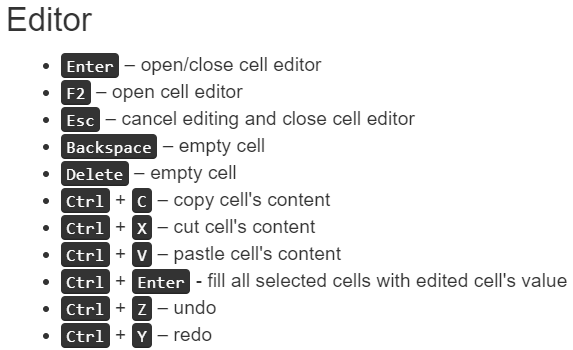

![]()
2. 사용할 수식
- 플랫 스프레드시트를 사용하면 플랫 스프레드시트를 탐색하는 데 도움이 되는 바로가기 가이드를 사용할 수 있습니다.
- 그것을 열려면 다음으로 이동하세요. 홈 -> 예약 -> 실험 -> 페이지 -> 플랫 스프레드시트 -> 편집 -> 지원되는 공식.
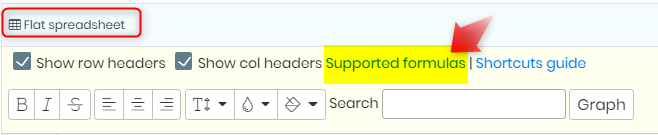
- 수식은 대문자 또는 소문자로 삽입할 수 있습니다(AVERAGE 또는 평균).
- 수식은 셀 번호 사이에 콜론이나 세미콜론을 사용하여 작동합니다.
- 아래 구문은 수식의 배열 및 설명입니다.
|
|
공식 |
상품 설명 |
|
1 |
ABS |
절대값은 +/- 기호가 없는 숫자입니다. *한 번에 개별 셀의 ABS만 찾을 수 있습니다. |
|
2 |
승인 |
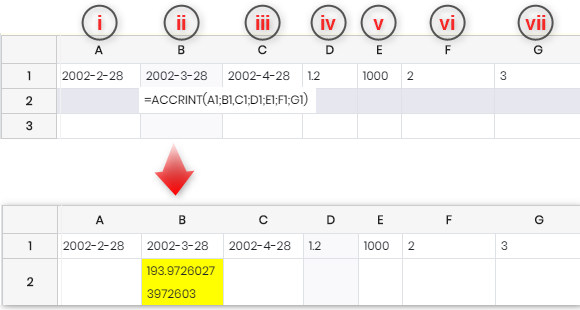
정기적으로 이자를 지급하는 유가 증권의 경과 이자를 계산합니다. 구문 : ACCRINT(발행; 우선_이자; 결제; 비율; 파; 빈도; 베이시스) 나. issue: 유가증권의 발행 날짜입니다. ii. first_interest: 유가증권의 첫 번째 이자 날짜입니다. iii. 결제일: 그때까지 발생한 이자를 계산하는 날짜입니다. iv. rate: 연간 명목 이자율(쿠폰 이자율) v. par: 유가증권의 액면가. vi. 빈도: 연간 이자 지급 횟수(1, 2 또는 4). vii. 기준: 옵션 목록에서 선택되며 연도 계산 방법을 나타냅니다. 기본값은 0 생략된 경우. 0 – 미국 방식(NASD), 각 12일씩 30개월 1 - 월의 정확한 일수, 일년의 정확한 일수 2 – 월의 정확한 일수, 연도는 360일입니다. 3 – 월의 정확한 일수, 연도는 365일입니다. 4 – 유럽식 방식, 각 12일씩 30개월
|
|
3 |
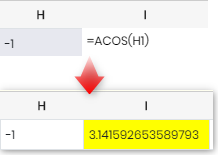
아코스 |
숫자의 역코사인(아크코사인)을 반환합니다.
|
|
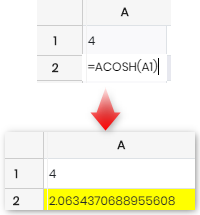
4 |
아코쉬 |
숫자의 역쌍곡선 코사인을 반환합니다.
|
|
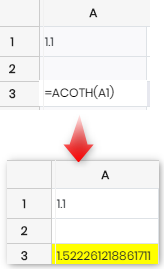
5 |
아코스 |
주어진 숫자의 역쌍곡선 코탄젠트를 반환합니다.
|
|
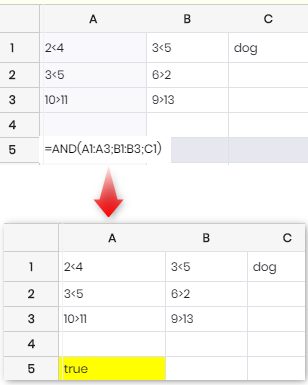
6 |
및 |
반품 TRUE 모든 주장을 고려한다면 TRUE및 그릇된 그렇지 않으면. 및 모든 값을 인수로 테스트하거나 참조된 각 셀에서 테스트하고 반환합니다. TRUE 만일 그들이 모두라면 TRUE. 어떤 값이든 0이 아닌 숫자 or 본문 ~로 간주됩니다 TRUE.
|
|
5 |
아라비아 말 |
로마 숫자(예: XIV)가 주어지면 아라비아 숫자(예: 14)를 반환합니다.
|
|
6 |
ASIN |
숫자의 역탄젠트(아크탄젠트)를 반환합니다. 예를 들어 셀에 수식을 입력하려면 =ASIN(셀 번호)를 입력하세요. |
|
7 |
아신 |
숫자의 역사인(아크사인)을 반환합니다. |
|
8 |
아탄 |
숫자의 역탄젠트(아크탄젠트)를 반환합니다. 예를 들어 셀에 수식을 입력하려면 =ATAN(셀 번호)를 입력하세요. |
|
9 |
아탄2 |
지정된 x 및 y 좌표에 대한 역탄젠트(아크탄젠트)를 반환합니다. 예를 들어 셀에 수식을 입력하려면 =ATAN2(셀 번호)를 입력하세요. |
|
10 |
아탄 |
숫자의 역쌍곡탄젠트를 반환합니다. 예를 들어 셀에 수식을 입력하려면 =ATANH(셀 번호)를 입력하세요. |
|
11 |
아베데브 |
값의 평균과 절대 편차의 평균을 반환합니다. 예를 들어 셀에 수식을 입력하려면 =AVEDEV(셀 번호:셀 번호:셀…)를 입력하세요. |
|
12 |
평균 |
텍스트를 무시하고 인수의 평균을 반환합니다. 예를 들어 셀에 수식을 입력하려면 =AVERAGE(셀 번호:셀 번호:셀…)를 입력하세요.
|
|
13 |
평균 |
텍스트(값은 0으로 계산됨)를 포함하여 인수의 평균을 반환합니다. AVERAGEA(값1; 값2; … 값30) value1 ~ value30은 최대 30개의 값 또는 범위이며 숫자, 텍스트 및 논리값을 포함할 수 있습니다. 텍스트는 다음과 같이 평가됩니다. 0. 논리값은 다음과 같이 평가됩니다. 1 (TRUE) and 0 (그릇된). 예를 들어 셀에 수식을 입력하려면 =AVERAGE(셀 번호:셀 번호:셀 번호…)를 입력하세요. |
|
14 |
AVERAGEIF |
지정된 기준을 충족하는 범위 내 모든 셀의 평균(산술 평균)을 반환합니다. 예를 들어 셀에 수식을 입력하려면 =AVERAGEIF(셀 번호:셀 번호:셀…)를 입력하세요. |
|
15 |
BASE |
지정된 기본 기수로 숫자의 텍스트 표현을 반환합니다. BASE(숫자; 기수; 최소 길이) 변환 번호 (양의 정수)를 텍스트로, 기본으로 어근 (2~36 사이의 정수), 문자 사용 0-9 및 AZ. 최소 길이 (선택 사항) 반환되는 최소 문자 수를 지정합니다. 필요한 경우 왼쪽에 0이 추가됩니다. 예를 들어 셀에 수식을 입력하려면 =BASE(셀 번호:셀 번호:셀…)을 입력하세요. |
|
16 |
베셀리 |
제1종 수정 베셀 함수를 계산합니다. 베셀리(x;n) 첫 번째 종류의 수정된 베셀 함수를 반환합니다. n, 평가 x. 제1종 변형 베셀 함수 In(x) = i-nJn(ix), 어디서 Jn *는 제1종 베셀 함수. 예를 들어 셀에 수식을 입력하려면 =BESSELI(셀 번호;셀 번호)를 입력하세요. |
|
17 |
베셀지 |
제1종 베셀 함수를 계산합니다. 베셀J(x; n) 제1종 순서의 베셀 함수를 반환합니다. n, 평가 x. 제1종 베셀 함수 Jn(x)는 베셀 미분 방정식의 해입니다. 예를 들어 셀에 수식을 입력하려면 =BESSELJ(셀 번호;셀 번호)를 입력하세요. |
|
18 |
베셀크 |
제2종 수정 베셀 함수를 계산합니다. 베셀크(x;n) x에서 평가된 n차의 수정된 제2종 베셀 함수를 반환합니다. 제2종 수정 베셀 함수(바셋 함수라고도 함)는 종종 다음과 같이 표시됩니다. Kn(x). 예를 들어 셀에 수식을 입력하려면 =BESSELJ(셀 번호;셀 번호)를 입력하세요. |
|
19 |
베셀리 |
제2종 베셀 함수(Neumann 또는 Weber 함수)를 계산합니다. 베셀리(x;n) x에서 평가된 n차의 두 번째 종류 베셀 함수를 반환합니다. 제2종 베셀 함수 Yn(x) (노이만이라고도 함) Nn(x) 또는 Weber 함수)는 원점에서 특이점인 베셀 미분 방정식의 해입니다. 예를 들어 셀에 수식을 입력하려면 =BESSELY(셀 번호;셀 번호)를 입력하세요. |
|
20 |
베타디스트 |
베타 분포의 누적 분포 함수 또는 확률 밀도 함수를 계산합니다. 에서 자세한 내용을 읽을 수 있습니다. 여기를 클릭해 문의해주세요. |
|
21 |
베타인 |
BETADIST 함수의 역함수를 계산합니다. 예를 들어 셀에 수식을 입력하려면 =BETAINV(셀 번호;셀 번호)를 입력하세요. |
|
22 |
BIN2DEC |
이진수를 십진수로 변환합니다. 예를 들어 셀에 수식을 입력하려면 =BIN2DEC(셀 번호)를 입력하세요. |
|
23 |
빈투헥스 |
2진수를 16진수로 변환합니다. 예를 들어 셀에 수식을 입력하려면 =BIN2HEX(셀 번호)를 입력하세요. |
|
24 |
2월 XNUMX일 |
2진수를 8진수로 변환합니다. 예를 들어 셀에 수식을 입력하려면 =BIN2OCT(셀 번호)를 입력하세요. |
|
25 |
바이노마디스트 |
이항 분포의 확률을 계산합니다. BINOMDIST(k; n; p; 모드) 예를 들어 셀에 수식을 입력하려면 =BINOMDIST(셀 번호; 셀 번호; 셀 번호)를 입력하세요. |
|
26 |
이항 거리 |
계산된 이항 분포 범위. 예 =BINOM.DIST.RANGE(60,0.75,48) 48번의 시도에서 60번의 성공 확률과 75%의 성공 확률(0.084 또는 8.4%)을 기반으로 하는 이항 분포를 반환합니다. 예를 들어 셀에 수식을 입력하려면 =BINOMDISTRANGE(셀 번호:셀 번호:셀 번호)를 입력하세요. |
|
27 |
비노민V |
NOM.INV(시행,probability_s,알파) BINOM.INV 함수 구문에는 다음 인수가 있습니다. – 평가판 : 필수입니다. 베르누이 시행 횟수. – Probability_s : 필수입니다. 각 시행의 성공 확률입니다. – 알파 : 필수입니다. 기준 값입니다. 예를 들어 셀에 수식을 입력하려면 =BINOMDINV(셀 번호:셀 번호:셀 번호)를 입력하세요. |
|
28 |
비트탠드 |
비트탠드 해당 인수의 비트별 및 이진 표현을 반환합니다. 여기서 셀 번호는 음수가 아닌 정수입니다. 예를 들어 셀에 수식을 입력하려면 =BITAND(셀 번호:셀 번호)를 입력하세요. |
|
29 |
비트시프트 |
이진 표현을 반환합니다. a 시프트 된 n 위치는 왼쪽으로. 여기서 하나의 셀 번호는 음수가 아닌 정수이고 다른 셀 번호는 정수입니다. 예를 들어 셀에 수식을 입력하려면 =BITLSHIFT(셀 번호:셀 번호)를 입력하세요. |
|
30 |
비토르 |
해당 인수의 비트별 또는 이진 표현을 반환합니다. 예를 들어 셀에 수식을 입력하려면 =BITOR(셀 번호;셀 번호)를 입력하세요. 여기서 셀 번호는 음수가 아닌 정수입니다. |
|
31 |
비트시프트 |
이진 표현을 반환합니다. a 시프트 된 n 오른쪽에 위치. 참고: 만약 n 음수이고, 비트시프트 ABS(n) 위치. 예를 들어 셀에 수식을 입력하려면 =BITRSHIFT(셀 번호;셀 번호)를 입력하세요. 여기서 하나의 셀 번호는 음수가 아닌 정수이고 다른 셀 번호는 정수입니다. |
|
32 |
비트소르 |
인수의 비트별 배타적 또는 이진 표현을 반환합니다. 예를 들어 셀에 수식을 입력하려면 =BITXOR(셀 번호;셀 번호)를 입력하세요. 여기서 셀 번호는 음수가 아닌 정수입니다. |
|
33 |
천장 |
다른 숫자의 배수로 반올림된 숫자를 반환합니다. 구문 : CEILING(숫자; 다중; 모드) – number는 mult의 배수로 반올림될 숫자입니다. – 모드가 0이거나 생략된 경우 CEILING은 위(크거나 같음) 숫자의 배수로 반올림됩니다. mode가 0이 아닌 경우 CEILING은 0에서 멀어지는 방향으로 반올림됩니다. 이는 음수에만 해당됩니다. 음수가 있고 MS Excel로 내보내려는 경우 호환성을 위해 mode=1을 사용하십시오. MS Excel에서 이 함수는 두 개의 인수만 사용합니다. 수식을 입력하려면 =CEILING(셀 번호;셀 번호;셀 번호)를 입력하세요. |
|
34 |
천장수학 |
숫자를 가장 가까운 정수 또는 가장 가까운 유효 배수로 반올림합니다. 구문 : CEILING.MATH(숫자, [유의성], [모드]) CEILING.MATH 함수 구문에는 다음 인수가 있습니다. – 번호 *필수입니다. 숫자는 9.99E+307보다 작고 -2.229E-308보다 커야 합니다. – 의미 *선택 사항. Number를 반올림할 배수입니다. – 모드 *선택 사항. 음수의 경우 숫자가 0에 가깝게 반올림되는지 또는 0에서 멀어지는지 여부를 제어합니다. 수식을 입력하려면 =CEILINGMATH(셀 번호:셀 번호:셀 번호)를 입력하세요. |
|
35 |
천장 정밀함 |
숫자를 주어진 배수로 반올림합니다. CEILING 함수와 달리 CEILING.MATH의 기본값은 1의 배수이며 항상 음수를 XNUMX 방향으로 반올림합니다. 수식을 입력하려면 =CEILING(셀 번호;셀 번호;셀 번호)를 입력하세요. 여기서 하나의 셀 번호는 반올림할 번호이고 다른 하나는 반올림할 때 사용할 여러 개를 입력하는 것입니다. 기본값은 1입니다. 두 번째 숫자는 선택 사항입니다. |
|
36 |
숯 |
문자 코드가 주어지면 단일 텍스트 문자를 반환합니다. 구문 : CHAR(숫자) number는 1-255 범위의 문자 코드입니다. CHAR는 시스템의 문자 매핑(예: iso-8859-1, iso-8859-2, Windows-1252, Windows-1250)을 사용하여 반환할 문자를 결정합니다. 127보다 큰 코드는 이식이 불가능할 수 있습니다. =CHAR(셀번호) |
|
37 |
치스큐디스트 |
χ에 대한 값을 계산합니다.2-분포. 자세한 내용은 여기를 참조하세요. 링크를 클릭하십시오. |
|
38 |
CHISQINV |
CHISQDIST 함수의 역함수를 계산합니다. 구문 : 수식을 입력하려면 =CHISQINV(p; k) k는 χ에 대한 자유도입니다.2-분포. 제약조건: k는 양의 정수여야 합니다. p는 주어진 확률입니다. 제약조건: 0 ≤ p < 1 |
|
39 |
CODE |
텍스트 문자열의 첫 번째 문자에 대한 숫자 코드를 반환합니다. 구문 : 코드(텍스트) 0-255 범위에서 텍스트 문자열 text의 첫 번째 문자에 대한 숫자 코드를 반환합니다. 127보다 큰 코드는 시스템의 문자 매핑(예: iso-8859-1, iso-8859-2, Windows-1252, Windows-1250)에 따라 달라질 수 있으므로 이식이 불가능할 수 있습니다. 수식을 입력하려면 =CODE(셀 번호) |
|
40 |
결합 |
항목 하위 집합의 조합 수를 반환합니다. 구문 : 결합(n; k) n은 세트의 항목 수입니다. k는 세트에서 선택할 항목 수입니다. COMBIN은 이러한 항목을 선택하는 방법의 수를 반환합니다. 예를 들어 한 세트에 A, B, C 3개의 항목이 있는 경우 AB, AC, BC의 2가지 방법으로 3개의 항목을 선택할 수 있습니다. COMBIN은 다음 공식을 구현합니다. n!/(k!(n-k)!) 수식을 입력하려면 =COMBIN(셀 번호, 셀 번호) |
|
41 |
콤비나 |
항목 하위 집합의 조합 수를 반환합니다. 구문 : 콤비나(n;k) n은 세트의 항목 수입니다. k는 세트에서 선택할 항목 수입니다. COMBINA는 이러한 항목을 선택하는 고유한 방법의 수를 반환합니다. 여기서 선택 순서는 중요하지 않으며 항목 반복이 허용됩니다. 예를 들어 세트에 A, B, C 3개의 항목이 있는 경우 AA, AB, AC, BB, BC 및 CC의 2가지 방법으로 6개의 항목을 선택할 수 있습니다. AAA, AAB, AAC, ABB, ABC, ACC, BBB, BBC, BCC, CCC 등 3가지 방법으로 10가지 항목을 선택할 수 있습니다. COMBINA는 다음 공식을 구현합니다. (n+k-1)!/(k!(n-1)!) 수식을 입력하려면 =COMBINA(셀 번호, 셀 번호) |
|
42 |
복잡한 |
실수 부분과 허수 부분이 주어지면 복소수를 반환합니다. 구문 : COMPLEX(실수부분; 허수부분; 접미사) 복소수를 텍스트 형식으로 반환합니다. a+bi or a+bj. realpart와 imaginarypart는 숫자입니다. 접미사는 복소수의 허수부를 나타내는 선택적 텍스트 i 또는 j(소문자)입니다. 기본값은 i입니다. 수식을 입력하려면 =COMPLEX(셀 번호, 셀 번호, 셀 번호) |
|
43 |
사슬 같이 잇다 |
여러 텍스트 문자열을 하나의 문자열로 결합합니다. 구문 : 연결(텍스트1; 텍스트2; … 텍스트30) 함께 결합된 최대 30개의 텍스트 문자열 text1 – text30을 반환합니다. text1 – text30은 단일 셀 참조일 수도 있습니다. 앰퍼샌드 연산자 &는 함수 없이 수식에서 텍스트를 연결하는 데 사용될 수도 있습니다. 그것에 대해 자세히 알아보기 여기를 클릭해 문의해주세요. |
|
44 |
신뢰도표준 |
정규 분포를 사용하여 모집단 평균에 대한 신뢰 구간을 반환합니다. 구문 : CONFIDENCE.NORM(알파,표준_dev,크기) CONFIDENCE.NORM 함수 구문에는 다음 인수가 있습니다. – 알파 *필수입니다. 신뢰 수준을 계산하는 데 사용되는 유의 수준입니다. 신뢰 수준은 100*(1 – 알파)%입니다. 즉, 알파 0.05는 95% 신뢰 수준을 나타냅니다. – Standard_dev *필수입니다. 데이터 범위에 대한 모집단 표준 편차이며 알려진 것으로 가정됩니다. – 크기 *필수입니다. 표본 크기. 그것에 대해 자세히 알아보기 여기를 클릭해 문의해주세요. |
|
45 |
자신감 |
스튜던트 t 분포를 사용하여 모집단 평균에 대한 신뢰 구간을 반환합니다. 구문 : CONFIDENCE.T(알파,표준_dev,크기) CONFIDENCE.T 함수 구문에는 다음 인수가 있습니다. – 알파 *필수입니다. 신뢰 수준을 계산하는 데 사용되는 유의 수준입니다. 신뢰 수준은 100*(1 – 알파)%입니다. 즉, 알파 0.05는 95% 신뢰 수준을 나타냅니다. – Standard_dev *필수입니다. 데이터 범위에 대한 모집단 표준 편차이며 알려진 것으로 가정됩니다. – 크기 *필수입니다. 표본 크기. 그것에 대해 자세히 알아보기 여기를 클릭해 문의해주세요. |
|
46 |
변하게 하다 |
기존 유럽 국가 통화를 유로화로 변환합니다. 구문 : CONVERT(값; 통화1; 통화2) value는 변환할 통화 금액입니다. 통화1과 통화2는 각각 변환할 통화 단위입니다. 아래 표에 표시된 대로 통화의 공식 약어(예: "EUR")인 텍스트여야 합니다. 요율(유로당 표시)은 유럽연합 집행위원회에서 설정했습니다. 기존 통화는 2002년에 유로화로 대체되었습니다. 변환(100;"ATS";"EUR") 100 오스트리아 실링을 유로로 변환합니다. 그것에 대해 자세히 알아보기 여기를 클릭해 문의해주세요. |
|
47 |
CORREL |
두 데이터 세트의 피어슨 상관 계수를 반환합니다. 구문 : 코렐(x;y) 여기서 x와 y는 두 데이터 세트를 포함하는 범위 또는 배열입니다. 텍스트나 빈 항목은 무시됩니다. CORREL은 다음을 계산합니다. 평균은 어디에 있습니까? x,y. |
|
48 |
COS |
주어진 각도의 코사인을 반환합니다(라디안 단위). 예: COS(PI()/2) PI/0 라디안의 코사인인 2을 반환합니다. COS(라디안(60)) 0.5도의 코사인인 60를 반환합니다. |
|
49 |
곤봉 |
숫자의 쌍곡선 코사인을 반환합니다. 구문 : COSH(숫자) 숫자의 쌍곡선 코사인을 반환합니다. 예: 코스(0) 1의 쌍곡선 코사인인 0을 반환합니다. |
|
50 |
COT |
주어진 각도의 코탄젠트(라디안 단위)를 반환합니다. 구문 : COT(앵글) 각도의 (삼각) 코탄젠트, 즉 라디안 단위의 각도를 반환합니다. 각도의 코탄젠트를 도 단위로 반환하려면 RADIANS 함수를 사용하세요. 각도의 코탄젠트는 1을 해당 각도의 탄젠트로 나눈 것과 같습니다. 예: COT(PI()/4) PI/1 라디안의 코탄젠트인 4을 반환합니다. 유아용침대(라디안스(45)) 1도의 코탄젠트인 45을 반환합니다. |
|
51 |
COTH |
숫자의 쌍곡선 코탄젠트를 반환합니다. 구문 : COTH(숫자) 숫자의 쌍곡선 코탄젠트를 반환합니다. 예: COTH(1) 1의 쌍곡선 코탄젠트(약 1.3130)를 반환합니다. |
|
52 |
COUNT |
텍스트 항목을 무시하고 인수 목록의 숫자를 계산합니다. 구문 : 개수(값1; 값2; … 값30) value1 ~ value30은 계산할 값을 나타내는 최대 30개의 값 또는 범위입니다. 예 : 개수(2; 4; 6; “XNUMX”) 3, 2, 4은 숫자("6"은 텍스트)이므로 XNUMX을 반환합니다. |
|
53 |
쿤타 |
인수 목록에서 비어 있지 않은 값의 개수를 셉니다. 구문 : COUNTA(값1; 값2; … 값30) value1 ~ value30은 계산할 값을 나타내는 최대 30개의 값 또는 범위입니다. 예: 카운타(B1:B3) 여기서 셀 B1, B2, B3에는 1.1, =NA()가 포함되어 있으며 B3:B1의 셀 중 비어 있는 셀이 없기 때문에 apple은 3을 반환합니다. |
|
54 |
COUNTBLANK |
빈 셀의 수를 반환합니다. 구문 : COUNTBLANK(범위) 셀 범위 범위에 있는 빈 셀의 수를 반환합니다. 공백과 같은 빈 텍스트나 =””에서 반환된 것과 같이 길이가 0인 텍스트가 포함된 셀은 비어 있는 것처럼 보이더라도 비어 있는 것으로 간주되지 않습니다. 예: 카운트블랭크(A1:B2) 셀 A4, A1, B2 및 B1가 모두 비어 있으면 2를 반환합니다. |
|
55 |
카운티 |
지정된 조건을 충족하는 범위의 셀 수를 계산합니다. 구문 : COUNTIF(테스트_범위; 조건) test_range는 테스트할 범위입니다. 예: COUNTIF(C2:C8; “>=20”) C2:C8에서 내용이 20보다 크거나 같은 셀 수를 반환합니다. 그것에 대해 자세히 알아보기 여기를 클릭해 문의해주세요. |
|
56 |
카운티 |
COUNTIFS 함수는 여러 범위의 셀에 기준을 적용하고 모든 기준이 충족되는 횟수를 계산합니다. 구문 : COUNTIFS(기준_범위1, 기준1, [기준_범위2, 기준2]...) COUNTIFS 함수 구문에는 다음 인수가 있습니다. 기준_범위1 *필수입니다. 연관된 기준을 평가할 첫 번째 범위입니다. 기준1 *필수입니다. 계산할 셀을 정의하는 숫자, 표현식, 셀 참조 또는 텍스트 형식의 기준입니다. 예를 들어 기준은 32, ">32", B4, "사과" 또는 "32"로 표현될 수 있습니다. 기준_범위2, 기준2, … *선택사항. 추가 범위 및 관련 기준. 최대 127개의 범위/기준 쌍이 허용됩니다. |
|
58 |
카운트유니크 |
지정된 값 및 범위 목록에서 고유 값의 수를 셉니다. 구문 : COUNTUNIQUE(값1, [값2, …]) · value1 – 고유성을 고려할 첫 번째 값 또는 범위입니다. · 값2, … – [ 선택 사항 ] – 고유성을 위해 고려할 추가 값 또는 범위. |
|
59 |
공분산P |
이 문서에서는 Microsoft Excel에서 COVARIANCE.P 함수의 수식 구문과 사용법을 설명합니다. 두 데이터 세트의 각 데이터 요소 쌍에 대한 편차 곱의 평균인 모집단 공분산을 반환합니다. 공분산을 사용하여 두 데이터 세트 간의 관계를 확인합니다. 예를 들어, 소득이 높을수록 교육 수준이 높아지는지 여부를 조사할 수 있습니다. 구문 : 공분산.P(배열1,배열2) COVARIANCE.P 함수 구문에는 다음 인수가 있습니다. 배열1 필수. 정수의 첫 번째 셀 범위입니다. 배열2 필수입니다. 정수의 두 번째 셀 범위입니다. 그것에 대해 읽어보세요 여기를 클릭해 문의해주세요. |
|
60 |
공분산 |
두 데이터 세트의 각 데이터 요소 쌍에 대한 편차 곱의 평균인 표본 공분산을 반환합니다. 구문 : COVARIANCE.S(배열1,배열2) COVARIANCE.S 함수 구문에는 다음 인수가 있습니다. 배열1 필수. 정수의 첫 번째 셀 범위입니다. 배열2 필수입니다. 정수의 두 번째 셀 범위입니다. 그것에 대해 읽어보세요 여기를 클릭해 문의해주세요. |
|
61 |
CCS |
숫자의 코시컨트를 반환합니다. 구문 : SC(번호) 숫자의 코시컨트를 반환합니다. 예: CSC(0): 1의 코시컨트인 0을 반환합니다. |
|
62 |
CSCH |
숫자의 쌍곡 코시컨트를 반환합니다. 구문 : CSCH(번호) 숫자의 쌍곡코시컨트를 반환합니다. 예: CSCH(0): 1의 쌍곡코시컨트인 0을 반환합니다. |
|
63 |
CUMIPMT |
지정된 정기 지불로 대출금에 지불된 총 이자를 반환합니다. 구문 : CUMIPMT(비율; 기간 수; 현재 가치; 시작; 끝; 유형) rate: 기간당 이자율입니다. num기간: 해당 기간의 총 지불 기간 수입니다. 현재 가치: 빌린 초기 금액입니다. start: 포함할 첫 번째 기간입니다. 기간은 1부터 시작하여 번호가 매겨집니다. end: 포함할 마지막 기간입니다. 유형: 결제 시: 0 – 각 기간이 끝날 때. 1 – 각 기간 시작 시(기간 시작 시 지불 포함). 그것에 대해 읽어보세요 여기를 클릭해 문의해주세요. |
|
64 |
컴프린 |
지정된 정기 지불로 대출금에 대해 상환된 총 자본금을 반환합니다. 구문 : CUMPRINC(비율; 기간 수; 현재 가치; 시작; 종료; 유형) – rate: 기간별 이자율입니다. – num기간: 해당 기간의 총 지불 기간 수입니다. – 현재 가치: 초기에 빌린 금액입니다. – 시작: 포함할 첫 번째 기간입니다. 기간은 1부터 시작하여 번호가 매겨집니다. – 종료: 포함할 마지막 기간입니다. – 유형: 결제 시: 0 – 각 기간이 끝날 때. 1 – 각 기간 시작 시(기간 시작 시 지불 포함). 그것에 대해 읽어보세요 여기를 클릭해 문의해주세요. |
|
65 |
날짜 |
DATE(년; 월; 일) 날짜-시간 일련 번호로 표현된 날짜를 반환합니다. 연도는 1583에서 9956 사이 또는 0에서 99 사이의 정수입니다. 월과 일은 정수입니다. 월과 일자가 유효한 날짜 범위 내에 있지 않으면 아래와 같이 날짜가 '롤오버'됩니다. 예: 날짜(2007; 11; 9) 9년 2007월 XNUMX일 날짜를 반환합니다(날짜-시간 일련 번호로). 날짜(2007; 12; 32) 1년 2008월 32일을 반환합니다. 2007년 XNUMX월 XNUMX일이 유효하지 않으므로 날짜가 롤오버됩니다. |
|
66 |
날짜값 |
텍스트로 주어진 날짜로부터 날짜-시간 일련번호를 반환합니다. 구문 : DATEVALUE(날짜 텍스트) datetext는 텍스트로 표현되는 날짜입니다. DATEVALUE는 날짜로 읽도록 형식이 지정된 날짜-시간 일련 번호를 반환합니다. 예: 날짜값(“2007-11-23”) 39409년 23월 2007일의 날짜-시간 일련 번호인 XNUMX를 반환합니다(기본 날짜-시간 시작 날짜 가정). |
|
67 |
일 |
주어진 날짜의 일자를 반환합니다. 구문 : DAY(날짜) 날짜를 숫자(1-31)로 반환합니다. 날짜는 텍스트이거나 날짜-시간 일련번호일 수 있습니다. 일(“2008-06-04”) 4를 반환합니다. |
|
68 |
일 |
두 날짜 사이의 일수를 반환합니다. 구문 : DAYS(종료일, 시작일) startdate 및 enddate는 숫자 또는 텍스트(숫자 형식으로 변환됨) 날짜일 수 있습니다. DAYS는 종료일 – 시작일을 반환합니다. 결과는 부정적일 수 있습니다. 예: DAYS(“2008-03-03”; “2008-03-01”) 2년 1월 08일과 3년 08월 XNUMX일 사이의 일수인 XNUMX를 반환합니다. 일수(A1; A2) 여기서 셀 A1에는 날짜 2008-06-09가 포함되고 A2에는 2008-06-02가 포함되어 7이 반환됩니다. |
|
69 |
DAYS360 |
360년 XNUMX일을 사용하여 두 날짜 사이의 일수를 반환합니다. 구문 : DAYS360(종료일; 시작일; 메소드) startdate 및 enddate는 시작 날짜와 종료 날짜(텍스트 또는 날짜-시간 일련 번호)입니다. startdate가 enddate보다 이전인 경우 결과는 음수입니다. method는 선택적 매개변수입니다. 0이거나 생략된 경우 미국 증권 딜러 협회(NASD) 계산 방법이 사용됩니다. 1(또는 <>0)인 경우 유럽식 계산 방법이 사용됩니다. 계산에서는 모든 달이 30일이라고 가정하므로 12년(360개월)은 XNUMX일입니다. 만나다 재무 날짜 시스템 자세한 내용은. 예: DAYS360(“2008-02-29”; “2008-08-31”) 180, 즉 6일로 구성된 30개월을 반환합니다. |
|
70 |
DB |
고정율 정률법을 사용하여 특정 연도의 자산 감가상각액을 반환합니다. 구문 : DB(원가;잔존가치;수명;년;월1년) Originalcost: 자산의 초기 비용입니다. salvagevalue: 감가상각 종료 시의 가치입니다(자산의 잔존 가치라고도 함). 수명: 자산이 감가상각되는 기간(년)입니다. 연도: 감가상각이 계산되는 연도입니다. Month1styear: 첫 해의 개월 수(생략할 경우 기본값은 12) 그것에 대해 읽어보세요 여기를 클릭해 문의해주세요. |
|
71 |
DDB |
이중(또는 기타 요인) 체감법을 사용하여 특정 연도 동안 자산의 감가 상각액을 반환합니다. 구문 : DDB(원가;잔존가치;수명;연도;계수) Originalcost: 자산의 초기 비용입니다. salvagevalue: 감가상각 종료 시의 가치입니다(자산의 잔존 가치라고도 함). 수명: 자산이 감가상각되는 기간(년)입니다. 연도: 감가상각이 계산되는 연도입니다. 인수: 감가상각률을 설정하는 인수입니다(생략할 경우 2). 그것에 대해 읽어보세요 여기를 클릭해 문의해주세요. |
|
72 |
덱투빈 |
10진수를 2진수로 변환합니다. 구문 : DEC2BIN(숫자; 숫자) 주어진 512진수는 -511에서 XNUMX 사이여야 하며 텍스트 또는 숫자일 수 있으며, XNUMX진수를 텍스트로 반환합니다. 출력은 0의 보수 표현으로 최대 111111111비트를 포함하는 이진수입니다. 양수는 0~511(1111111111진수 1000000000~1을 나타내는 512비트)이고 음수는 XNUMX~XNUMX(XNUMX진수 -XNUMX~-XNUMX를 나타내는 XNUMX비트)입니다. numdigits는 반환할 자릿수를 지정하는 선택적 숫자입니다. 예: 2월9빈(XNUMX) 1001을 텍스트로 반환합니다. 2월9빈(“XNUMX”) 1001을 텍스트로 반환합니다. DEC2BIN은 텍스트로 주어진 십진수를 허용합니다. |
|
73 |
DEC2HEX |
10진수를 16진수로 변환합니다. 구문 : DEC2HEX(숫자; 숫자) 주어진 십진수는 -2 사이여야 하며 텍스트로 XNUMX진수를 반환합니다.39 및 239-1이 포함되며 텍스트나 숫자일 수 있습니다. 출력은 2의 보수 표현으로 최대 10자리의 16진수입니다. numdigits는 반환할 자릿수를 지정하는 선택적 숫자입니다. 예: 2월30HEX(XNUMX) 1E를 텍스트로 반환합니다. DEC2HEX(“30”) 1E를 텍스트로 반환합니다. DEC2HEX는 텍스트로 주어진 십진수를 허용합니다. |
|
74 |
2월XNUMX일 |
10진수를 8진수로 변환합니다. 구문 : DEC2OCT(숫자; 숫자) 주어진 2진수는 -XNUMX 사이여야 하며 텍스트로 XNUMX진수를 반환합니다.29 및 229-1이 포함되며 텍스트나 숫자일 수 있습니다. 결과는 2의 보수 표현으로 최대 10자리의 8진수입니다. numdigits는 반환할 자릿수를 지정하는 선택적 숫자입니다. 예: DEC2OCT(19) 23을 텍스트로 반환합니다. DEC2OCT(“19”) 23을 텍스트로 반환합니다. DEC2OCT는 텍스트로 주어진 XNUMX진수를 허용합니다. |
|
75 |
소수 |
주어진 텍스트 표현과 기본 기수를 사용하여 10진수를 반환합니다. 구문 : DECIMAL(텍스트; 기수) text는 기본 기수 기수(2에서 36 사이의 정수)를 사용하여 숫자를 나타내는 텍스트입니다. 선행 공백과 탭은 무시됩니다. 문자가 있는 경우 대문자 또는 소문자일 수 있습니다. 기수가 16(0진수 시스템)인 경우 선행 0x, XNUMXX, x 또는 X는 무시되고 후행 h 또는 H도 무시됩니다. 기수가 2(이진 시스템)인 경우 뒤에 오는 b 또는 B는 무시됩니다. 예: 십진수(“00FF”; 16) 255를 숫자(XNUMX진수 시스템)로 반환합니다. |
|
76 |
DEGREES |
라디안을 각도로 변환합니다. 구문 : DEGREES(라디안) 라디안은 각도로 변환할 라디안 단위의 각도입니다. 예: 학위(PI()) 180도를 반환 |
|
77 |
DELTA |
두 숫자가 같으면 1을 반환하고, 그렇지 않으면 0을 반환합니다. 구문 : DELTA(숫자1; 숫자2) 숫자 1과 숫자 2는 숫자입니다. 숫자 2가 생략되면 0으로 간주됩니다. 이 함수는 (수학적) 크로네커 델타 함수의 구현입니다. number1=number2는 1이나 0 대신 TRUE 또는 FALSE를 반환하지만 그 외에는 숫자 인수에 대해 동일합니다. 예: 델타(4; 5) 0를 반환합니다. 델타(4; A1) 셀 A1에 4가 포함되어 있으면 1을 반환합니다. |
|
78 |
데브스큐 |
평균과의 편차 제곱의 합을 반환합니다. 구문 : DEVSQ(번호1; 번호2; … 번호30) number1 ~ number30은 최대 30개의 숫자 또는 숫자를 포함하는 범위입니다. DEVSQ는 모든 숫자의 평균을 계산한 다음 해당 평균에서 각 숫자의 제곱 편차를 합산합니다. N 값의 경우 계산 공식은 다음과 같습니다. 예: DEVSQ(1; 3; 5) (-8)로 계산되어 2을 반환합니다.2 + 0 + (2)2. |
|
79 |
달러 |
현지 통화 형식으로 숫자를 나타내는 텍스트를 반환합니다. 구문 : DOLLAR(숫자, 소수점 이하) 숫자를 통화로 나타내는 텍스트를 반환합니다. 소수(선택 사항, 생략하면 2로 가정)는 소수 자릿수를 설정합니다. 도구 – 옵션 – 언어 설정 – 언어 – '기본 통화'는 사용할 통화를 설정합니다(일반적으로 해당 지역의 통화). 예: 달러(255) 통화가 미국 달러인 경우 $255.00를 반환합니다. 달러(367.456; 2) 통화가 미국 달러인 경우 $367.46를 반환합니다. |
|
80 |
달러 |
숫자의 분수 표현을 십진수로 변환합니다. 구문 : DOLLARDE(분수대표; 분모) Fractionalrep: 분수 표현. 예를 들어 때때로 증권 가격은 2.03으로 표현될 수 있는데, 이는 2달러의 3달러와 16/XNUMX을 의미합니다. 분모: 분모 – 예를 들어 위 예에서는 16입니다. DOLLARDE는 분수 표현을 십진수로 변환합니다. 이름에도 불구하고 통화가 아닌 숫자를 반환합니다. 그 반대는 DOLLARFR입니다. 예: 달러(2.03; 16) returns 2.1875 as a number. 2 + 3/16 equals 2.1875. |
|
81 |
달러FR |
10진수를 해당 숫자의 분수 표현으로 변환합니다. 구문 : DOLLARFR(소수점, 분모) 십진수: 십진수. 분모: 분수 표현의 분모입니다. 예를 들어 때때로 증권 가격은 2.03으로 표현될 수 있는데, 이는 2달러의 3달러와 16/2.1875을 의미하는 분수 표현입니다. 십진수로는 XNUMX이다. DOLLARFR은 소수 표현을 분수 표현으로 변환합니다. 이름에도 불구하고 통화가 아닌 숫자를 반환합니다. 그 반대는 DOLLARDE입니다. 예: 달러FR(2.1875; 16) returns 2.03 as a number. 2 + 3/16 equals 2.1875. |
|
83 |
날짜 |
몇 개월 후의 날짜를 반환합니다. 구문 : EDATE(시작일; 개월) 개월은 시작 날짜에 추가되는 개월 수입니다. 날짜는 새 달의 일수(해당 달의 마지막 날이 되는 경우)를 초과하지 않는 한 변경되지 않습니다. 월은 음수일 수 있습니다. 예: EDATE("2008-10-15"; 2) 15년 08월 XNUMX일을 반환합니다. EDATE("2008-05-31"; -1) 30년 08월 30일에 반환됩니다. XNUMX월은 XNUMX일밖에 남지 않았습니다. |
|
84 |
효과 |
연간 명목 이자율과 복리 기간 수를 고려하여 연간 실질 이자율을 계산합니다. 구문 : 효과(명목_이자율, 기간_연간) · 명목상_이자율 – 연간 명목 이자율입니다. · period_per_year – 연간 복리 기간 수입니다. 그것에 대해 읽어보세요 여기를 클릭해 문의해주세요. |
|
85 |
EOMONTH |
한 달의 마지막 날의 날짜를 반환합니다. 구문 : EOMONTH(시작일; 월 추가) addmonths는 새 날짜를 제공하기 위해 startdate(텍스트 또는 날짜-시간 일련 번호로 제공됨)에 추가할 월 수입니다. 이 새 날짜에 대해 EOMONTH는 해당 월의 마지막 날 날짜를 날짜-시간 일련 번호로 반환합니다. addmonths는 양수(미래), 0 또는 음수(과거)일 수 있습니다. 예: EOMONTH(“2008-02-14”; 0) 39507을 반환하며 이는 29Feb08로 형식화될 수 있습니다. 2008년은 윤년이다. |
|
86 |
상속 |
오류 함수(가우스 오류 함수)를 계산합니다. 구문 : ERF(번호1; 번호2) number2가 생략되면 0과 number1 사이에서 계산된 오류 함수를 반환하고, 그렇지 않으면 number1과 number2 사이에서 계산된 오류 함수를 반환합니다. Gauss 오류 함수라고도 알려진 오류 함수는 ERF(x) 같이: ERF(x1; x2)는 ERF(x2) – ERF(x1). 예: ERF(0.5) 0.520499877813를 반환합니다. ERF(0.2; 0.5) 0.297797288603를 반환합니다. |
|
87 |
ERFC |
상보 오류 함수(상보 가우스 오류 함수)를 계산합니다. 구문 : ERFC(번호) 반환 오류 기능 숫자와 무한대 사이에서 계산됩니다. 즉, 숫자에 대한 상보 오류 함수입니다. ERFC(x) = 1 – ERF(x). 예: ERFC(0.5) 0.479500122187을 반환합니다. |
|
88 |
에도 |
0에서 먼 쪽의 숫자를 다음 짝수로 반올림합니다. 구문 : 짝수(숫자) 0에서 멀어지는 다음 짝수로 반올림된 숫자를 반환합니다. 예: 짝수(2.3) 4를 반환합니다. |
|
89 |
정확한 |
두 텍스트 문자열이 동일하면 TRUE를 반환합니다. 구문 : 정확함(텍스트1; 텍스트2) 텍스트 문자열 text1과 text2가 정확히 동일한 경우(대소문자 포함) TRUE를 반환합니다. 예: EXACT(“빨간색 자동차”; “빨간색 자동차”) TRUE를 반환합니다. EXACT(“빨간색 자동차”; “빨간색 자동차”) 거짓을 반환합니다. |
|
90 |
확장자 |
지수 분포의 값을 계산합니다. 구문 : EXPONDIST(x; λ; 모드) 지수 분포는 매개변수가 λ(비율)인 연속 확률 분포입니다. λ는 0보다 커야 합니다. 모드가 0이면 EXPONDIST는 지수 분포의 확률 밀도 함수를 계산합니다. mode가 1이면 EXPONDIST는 지수 분포의 누적 분포 함수를 계산합니다. 예: EXPONDIST(0; 1; 0) 1을 반환합니다. EXPONDIST(0; 1; 1) 0을 반환합니다. |
|
91 |
그릇된 |
논리값 FALSE를 반환합니다. 구문 : 거짓() FALSE() 함수에는 인수가 없으며 항상 논리값 FALSE를 반환합니다. 예: 거짓() 거짓을 반환합니다. 아님(거짓()) TRUE를 반환합니다. |
|
92 |
FDIST |
F-분포의 값을 계산합니다. 구문 : FDIST(x; r1; r2) 양의 정수인 r1과 r2는 F-분포의 자유도 매개변수입니다. x는 0보다 크거나 같아야 합니다. FDIST는 F-분포에 대한 확률 밀도 함수의 오른쪽 꼬리 영역을 반환하고 다음을 계산합니다. 예: FDIST(1; 4; 5) 대략 0.485657을 반환합니다. |
|
93 |
핀브 |
FDIST 함수의 역함수를 계산합니다. 구문 : FINV(p; r1; r2) FDIST(x; r1; r2)가 p가 되는 값 x를 반환합니다. 매개변수 r1 및 r2(자유도)는 양의 정수입니다. p는 0보다 크고 1보다 작거나 같아야 합니다. 예: FINV(0.485657; 4; 5) 대략 1을 반환합니다. |
|
94 |
어부 |
Fisher 변환 값을 계산합니다. 구문 : 피셔(r) r에서 Fisher 변환 값을 반환합니다(-1 < r < 1). 이 함수는 다음을 계산합니다. 예: 피셔(0) 0을 반환합니다. |
|
95 |
피셔린브 |
FISHER 변환의 역함수를 계산합니다. 구문 : 피셔INV(z) FISHER(r)이 z가 되도록 r 값을 반환합니다. 이 함수는 다음을 계산합니다. 예: 피셔INV(0) 0을 반환합니다. |
|
96 |
IF |
IF 함수는 Excel에서 가장 많이 사용되는 함수 중 하나이며 이를 사용하면 값과 예상한 값을 논리적으로 비교할 수 있습니다. 자세한 내용은 확인하십시오 여기에서 지금 확인해 보세요. |
|
97 |
INT |
숫자를 가장 가까운 정수로 내림합니다. 구문 : INT(숫자) 숫자를 가장 가까운 정수로 내림하여 반환합니다. 음수는 아래의 정수로 반올림됩니다. -1.3은 -2로 반올림됩니다. 예: 지능(5.7) 5을 반환합니다. 지능(-1.3) -2를 반환합니다. |
|
98 |
짝수이다 |
값이 짝수이면 TRUE를 반환하고, 값이 홀수이면 FALSE를 반환합니다. 구문 : ISEVEN(값) value는 확인할 값입니다. 값이 정수가 아닌 경우 소수점 이하의 모든 숫자는 무시됩니다. 값의 부호도 무시됩니다. 예: 아이세븐(48) TRUE를 반환합니다. 아이세븐(33) 거짓을 반환합니다. |
|
99 |
ISODD |
값이 홀수이면 TRUE를 반환하고, 값이 짝수이면 FALSE를 반환합니다. 구문 : ISODD(값) value는 확인할 값입니다. 값이 정수가 아닌 경우 소수점 이하의 모든 숫자는 무시됩니다. 값의 부호도 무시됩니다. 예: ISODD(33) TRUE를 반환합니다. ISODD(48) 거짓을 반환합니다. |
|
100 |
LN |
숫자의 자연 로그를 반환합니다. 구문 : LN(숫자) 자연로그를 반환합니다. e)의 숫자, 그것이 바로 e 숫자가 같아야합니다. 수학적 상수 e 대략 2.71828182845904입니다. 예: 린(3) 3의 자연 로그(약 1.0986)를 반환합니다. |
|
101 |
LOG |
지정된 밑수에 대한 숫자의 로그를 반환합니다. 구문 : LOG(숫자; 기본) 숫자의 밑수에 대한 로그를 반환합니다. 예: 로그(10; 3) 3의 밑이 10인 로그(약 2.0959)를 반환합니다. |
|
102 |
로그10 |
숫자의 밑이 10인 로그를 반환합니다. 구문 : LOG10(번호) 밑수 10의 로그를 반환합니다. 예: 로그10(5) 10의 밑이 5인 로그(약 0.69897)를 반환합니다. |
|
103 |
MAX |
텍스트 항목을 무시하고 인수 목록의 최대값을 반환합니다. 구문 : MAX(숫자1; 숫자2; … 숫자30) number1 ~ number30은 최대 30개의 숫자 또는 숫자를 포함하는 범위입니다. 예: 최대(2; 6; 4) 목록에서 가장 큰 값인 6을 반환합니다. |
|
104 |
MAXA |
텍스트 및 논리 항목을 포함하여 인수 목록의 최대값을 반환합니다. 구문 : MAXA(값1; 값2; … 값30) value1 ~ value30은 최대 30개의 값 또는 범위이며 숫자, 텍스트 및 논리값을 포함할 수 있습니다. 텍스트는 0으로 평가됩니다. 논리값은 1(TRUE)과 0(FALSE)으로 평가됩니다. 예: MAXA(2; 6; 4) 목록에서 가장 큰 값인 6을 반환합니다. |
|
105 |
MEDIAN |
숫자 집합의 중앙값을 반환합니다. 구문 : MEDIAN(숫자1; 숫자2; … 숫자30) number1 ~ number30은 최대 30개의 숫자 또는 숫자를 포함하는 범위입니다. MEDIAN은 숫자의 중앙값(중간값)을 반환합니다. 숫자의 개수가 홀수이면 이것이 정확한 중간 값입니다. 개수가 짝수이면 가운데 두 값의 평균이 반환됩니다. 예: 중앙값(1; 5; 9; 20; 21) 정확히 중간에 있는 숫자인 9를 반환합니다. |
|
106 |
MIN |
텍스트 항목을 무시하고 인수 목록의 최소값을 반환합니다. 구문 : MIN(숫자1; 숫자2; … 숫자30) number1 ~ number30은 최대 30개의 숫자 또는 숫자를 포함하는 범위입니다. 예: 최소(2; 6; 4) 목록에서 가장 작은 값인 2를 반환합니다. 최소(B1:B3) where cells B1, B2, B3 contain 1.1, 2.2, and apple returns 1.1. |
|
107 |
미나 |
텍스트 및 논리 항목을 포함하여 인수 목록의 최소값을 반환합니다. 구문 : MINA(값1; 값2; … 값30) value1 ~ value30은 최대 30개의 값 또는 범위이며 숫자, 텍스트 및 논리값을 포함할 수 있습니다. 텍스트는 0으로 평가됩니다. 논리값은 1(TRUE)과 0(FALSE)으로 평가됩니다. 예: 미나(2; 6; 4) 목록에서 가장 작은 값인 2를 반환합니다. 미나(B1:B3) 여기서 셀 B1, B2, B3에는 3, 4가 포함되고 apple은 텍스트 값인 0을 반환합니다. |
|
108 |
MOD |
하나의 정수를 다른 정수로 나눈 나머지를 반환합니다. 구문 : MOD(숫자; 제수) 정수 인수의 경우 이 함수는 숫자 모듈로 제수, 즉 숫자를 제수로 나눈 나머지를 반환합니다. 이 함수는 number – divisor * INT( number/divisor) 로 구현되며 이 공식은 인수가 정수가 아닌 경우 결과를 제공합니다. 예: MOD(22; 3) 반품 1, 나머지는 22 로 나누어진다 3. |
|
109 |
않습니다. |
논리값을 반대로 바꿉니다. 보고 TRUE 인수가 그릇된및 그릇된 인수가 TRUE. 구문 : NOT(논리_값) 여기서 logic_value는 되돌릴 논리값입니다. 예: 사실이 아니다() ) 거짓을 반환합니다. |
|
110 |
ODD |
숫자를 0에서 멀어지는 방향으로 다음 홀수 정수로 반올림합니다. 구문 : 홀수) 0에서 멀어지는 다음 홀수 정수로 반올림된 숫자를 반환합니다. 예: 홀수(1.2) 3를 반환합니다. |
|
111 |
OR |
인수 중 하나라도 TRUE로 간주되면 TRUE를 반환하고 그렇지 않으면 FALSE를 반환합니다. 구문 : OR(인수1; 인수2 …인수30) 인수1부터 인수30까지는 최대 30개의 인수가 있으며, 각 인수는 논리적 결과나 값이거나 셀이나 범위에 대한 참조일 수 있습니다. OR은 모든 값(인수 또는 참조된 각 셀의 값)을 테스트하고 그 중 하나라도 TRUE이면 TRUE를 반환합니다. 0이 아닌 숫자는 모두 TRUE로 간주됩니다. 범위에 있는 모든 텍스트 셀은 무시됩니다. 예: 또는(참; 거짓) TRUE를 반환합니다. |
|
112 |
PI |
소수점 3.14159265358979자리까지의 수학 상수 PI 값인 14를 반환합니다. 구문 : 피() 예: 피() 3.14159265358979을 반환합니다. |
|
113 |
힘 |
거듭제곱된 숫자를 반환합니다. 구문 : POWER(숫자; 거듭제곱) 숫자를 반환합니다힘, 그것은 거듭제곱의 숫자입니다. 지수 연산자 ^를 사용하여 동일한 결과를 얻을 수 있습니다. 숫자^제곱 예: 힘(4; 3) 64의 4제곱인 3를 반환합니다. |
|
114 |
라운드 |
숫자를 특정 정밀도로 반올림합니다. 구문 : ROUND(숫자, 자릿수) 소수점 이하 자리까지 반올림된 숫자를 반환합니다. 장소가 생략되거나 10인 경우 함수는 가장 가까운 정수로 반올림됩니다. 장소가 음수인 경우 함수는 가장 가까운 100, 1000, XNUMX 등으로 반올림됩니다. 이 함수는 가장 가까운 숫자로 반올림됩니다. 보다 ROUNDDOWN 및 ROUNDUP 대안을 위해. 예: 라운드(2.348; 2) 2.35을 반환합니다. 라운드(2.348; 0) 2을 반환합니다. |
|
115 |
ROUNDDOWN |
숫자를 0에 가까운 특정 정밀도로 내림합니다. 구문 : ROUNDDOWN(숫자, 자릿수) 소수점 자리까지 반올림(10 방향)하여 숫자를 반환합니다. 장소가 생략되거나 100인 경우 함수는 정수로 내림됩니다. Places가 음수이면 함수는 다음 1000, XNUMX, XNUMX 등으로 내림됩니다. 이 함수는 반올림됩니다. XNUMX을 향해. 참조 ROUNDUP 및 라운드 대안을 위해. 예: ROUNDDOWN(1.234; 2) 1.23을 반환합니다. |
|
116 |
ROUNDUP |
숫자를 0에서 멀어지도록 특정 정밀도로 반올림합니다. 구문 : ROUNDUP(숫자, 자릿수) 소수점 자리까지 반올림(10에서 먼 쪽)하여 숫자를 반환합니다. 장소가 생략되거나 100인 경우 함수는 정수로 반올림됩니다. Places가 음수이면 함수는 다음 1000, XNUMX, XNUMX 등으로 반올림됩니다. 이 함수는 반올림됩니다. 0에서 멀리. 참조 ROUNDDOWN 및 라운드 대안을 위해. 예: ROUNDUP(1.1111; 2) 1.12을 반환합니다. ROUNDUP(1.2345; 1) 1.3을 반환합니다. |
|
117 |
죄 |
주어진 각도의 사인을 반환합니다(라디안 단위). 구문 : SIN(각도) 각도의 (삼각) 사인, 즉 라디안 단위의 각도를 반환합니다. 각도의 사인을 도 단위로 반환하려면 RADIANS 함수를 사용하세요. 예: SIN(PI()/2) PI/1 라디안의 사인인 2을 반환합니다. SIN(라디안(30)) 0.5도의 사인인 30를 반환합니다. |
|
118 |
신 |
숫자의 쌍곡선 사인을 반환합니다. 구문 : SINH(숫자) 숫자의 쌍곡선 사인을 반환합니다. 예: 신(0) 0의 쌍곡사인인 0을 반환합니다. |
|
119 |
분리 |
지정된 수의 부분 문자열을 포함하는 0부터 시작하는 1차원 배열을 반환합니다. 자세한 내용은 여기를 클릭해 문의해주세요. |
|
120 |
SQRT |
숫자의 양의 제곱근을 반환합니다. 구문 : SQRT(번호) 숫자의 양의 제곱근을 반환합니다. 숫자는 양수여야 합니다. 예: 스퀘어(16) 4를 반환합니다. SQRT(-16) 반환 잘못된 인수 오류. |
|
121 |
SQRTPI |
(PI 곱하기 숫자)의 제곱근을 반환합니다. 구문 : SQRTPI(숫자) ( PI 곱하기 숫자 )의 양의 제곱근을 반환합니다. 이는 SQRT(PI()*번호)와 동일합니다. 예: SQRTPI(2) (2PI)의 제곱근(약 2.506628)을 반환합니다. |
|
122 |
SUM |
셀의 내용을 합산합니다. 구문 : SUM(숫자1; 숫자2; … 숫자30) number1 ~ number30은 합계를 계산할 최대 30개의 숫자 또는 숫자의 범위/배열입니다. SUM은 범위나 배열 내의 모든 텍스트나 빈 셀을 무시합니다. SUM은 지정된 조건이 true인 셀을 합산하거나 계산하는 데에도 사용할 수 있습니다. 조건부 계산 및 합산. 예: 합계(2; 3; 4) returns 9, because 2+3+4 = 9. |
|
123 |
수미 |
범위에 있는 셀의 내용을 조건부로 합산합니다. 구문 : SUMIF(테스트_범위; 조건; 합계_범위) 이 함수는 조건을 충족하는 test_range 범위의 셀을 식별하고 sum_range 범위의 해당 셀을 합산합니다. sum_range를 생략하면 test_range의 셀이 합산됩니다. 더 많은 정보를 읽으려면 여기를 클릭해 문의해주세요. |
|
124 |
사명 |
여러 기준을 충족하는 모든 인수를 추가합니다. 예를 들어, SUMIFS를 사용하여 (1) 단일 우편 번호에 거주하고 (2) 이익이 특정 달러 가치를 초과하는 국가의 소매업체 수를 합산합니다. 자세한 내용은 여기를 클릭해 문의해주세요. |
|
125 |
SUMPRODUCT |
해당 배열 요소의 곱의 합계를 반환합니다. 구문 : SUMPRODUCT(배열1; 배열2; … 배열30) array1 ~ array30은 해당 요소를 곱할 동일한 크기의 최대 30개 배열 또는 범위입니다. SUMPRODUCT는 다음에 대해 반환합니다. i 배열의 요소. SUMPRODUCT를 사용하여 두 벡터의 스칼라 곱을 계산할 수 있습니다. 예: 합계(A1:B2; F1:G2) returns A1*F1 + B1*G1 + A2*F2 + B2*G2. 그것에 대해 자세히 알아보기 여기를 클릭해 문의해주세요. |
|
126 |
숨큐 |
인수의 제곱의 합을 반환합니다. 구문 : SUMSQ(숫자1; 숫자2; …. 숫자30) number1부터 number30까지 제곱한 후 합산되는 최대 30개의 숫자 또는 숫자 범위입니다. 예: SUMSQ(2; 3; 4) 29*2 + 2*3 + 3*4인 4를 반환합니다. |
|
127 |
SUMX2MY2 |
두 행렬의 해당 제곱 요소 간 차이의 합을 반환합니다. 구문 : SUMX2MY2(x;y) x와 y는 동일한 크기의 배열 또는 범위입니다. SUMX2MY2는 다음을 계산합니다. i 배열의 요소. 고급 주제: SUMX2MY2는 매개변수 x 및 y를 다음과 같이 평가합니다. 배열 수식 하지만 배열 수식으로 입력할 필요는 없습니다. 즉, Cntrl-Shift-Enter 대신 Enter 키를 사용하여 입력할 수 있습니다. 아래 예를 참조하세요. 예: SUMX2MY2(A1:A2; {2|1}) 여기서 셀 A1과 A2에는 각각 4와 3이 포함되어 있으며 다음을 반환합니다. (42-22) + (32-12) = 20. 그것에 대해 자세히 알아보기 여기를 클릭해 문의해주세요. |
|
128 |
SUMX2PY2 |
두 행렬의 모든 요소에 대한 제곱의 합을 반환합니다. 구문 : SUMX2PY2(x;y) x와 y는 동일한 크기의 배열 또는 범위입니다. SUMX2PY2는 다음을 계산합니다. i 배열이나 범위의 요소. 고급 주제: SUMX2PY2는 매개변수 x 및 y를 다음과 같이 평가합니다. 배열 수식 하지만 배열 수식으로 입력할 필요는 없습니다. 즉, Cntrl-Shift-Enter 대신 Enter 키를 사용하여 입력할 수 있습니다. 아래 예를 참조하세요. 예: SUMX2PY2(A1:A2; {2|1}) 여기서 셀 A1과 A2에는 각각 4와 3이 포함되어 있으며 다음을 반환합니다. (42+22) + (32+12) = 30. 자세히 알아보기 여기를 클릭해 문의해주세요. |
|
129 |
SUMXMY2 |
두 행렬의 해당 요소 간 차이 제곱의 합을 반환합니다. 구문 : SUMXMY2(x;y) x와 y는 동일한 크기의 배열 또는 범위입니다. SUMXMY2는 다음을 계산합니다. i 배열의 요소. |
|
130 |
TAN |
주어진 각도의 탄젠트를 반환합니다(라디안 단위). 구문 : 탄(각도) 각도의 (삼각) 탄젠트, 즉 라디안 단위의 각도를 반환합니다. 각도의 탄젠트를 도 단위로 반환하려면 RADIANS 함수를 사용하세요. 예: 탄(PI()/4) PI/1 라디안의 탄젠트인 4을 반환합니다. |
|
131 |
탄 |
숫자의 쌍곡선 탄젠트를 반환합니다. 구문 : TANH(숫자) 숫자의 쌍곡선 탄젠트를 반환합니다. 예: 탄(0) 0의 쌍곡선 탄젠트인 0을 반환합니다. |
|
132 |
TRUE |
논리값 TRUE를 반환합니다. 구문 : 진실() TRUE() 함수에는 인수가 없으며 항상 논리값 TRUE를 반환합니다. 예: 진실() TRUE를 반환합니다. |
|
133 |
트렁크 |
소수 자릿수를 제거하여 숫자를 자릅니다. 구문 : TRUNC(숫자, 자릿수) 소수점 이하 최대 자릿수를 반환합니다. 초과된 소수점 이하 자릿수는 부호에 관계없이 간단히 제거됩니다. TRUNC(number; 0)은 양수의 경우 INT(number)처럼 동작하지만 음수의 경우 사실상 XNUMX쪽으로 반올림됩니다. 예: 트렁크(1.239; 2) 1.23을 반환합니다. 9가 사라졌습니다. |
|
134 |
무료 |
XOR 함수는 모든 인수의 논리적 Exclusive Or를 반환합니다. 구문 : XOR(논리1, [논리2],…) XOR 함수 구문에는 다음 인수가 있습니다. Logical1, logic2,… 논리 1은 필수이며 이후의 논리 값은 선택 사항입니다. 테스트하려는 조건은 1~254개이며 TRUE 또는 FALSE일 수 있으며 논리값, 배열 또는 참조일 수 있습니다. 이 읽어주십시오 링크 |


![]()
3. 그래프 만들기
- 자세한 내용은 KB를 참조하세요. 플랫 스프레드시트에서 그래프를 만드는 방법.
![]()
관련 주제 :
- 자세한 내용은 KB를 읽어보세요. zoho 스프레드시트란 무엇이며 어떻게 활성화하나요?
- 자세히 알아보려면 KB를 읽어보세요. 플랫 스프레드시트에서 그래프를 만드는 방법.
- 우리의 읽기 설명서에 LabCollector.
- KB를 확인하세요. ELN 주형.
- 방법 알아보기 ELN 워크 플로.
- 에 대한 자세한 내용을 읽어보십시오 책, 실험, 페이지를 만드는 방법
- 우리의 읽기 서식 있는 텍스트 편집기를 사용하는 방법을 알아보려면 KB를 참조하세요. in ELN.
- 우리의 확인 실험 내용에 대해 읽을 수 있는 KB in ELN.
- 읽기 책 안에는 무엇이 들어있나요? in ELN.
